一. 部署架构
redis:两节点主从
mysql:两节点双主
n9e:两个节点,4层代理负载均衡到两节点
二. 现象
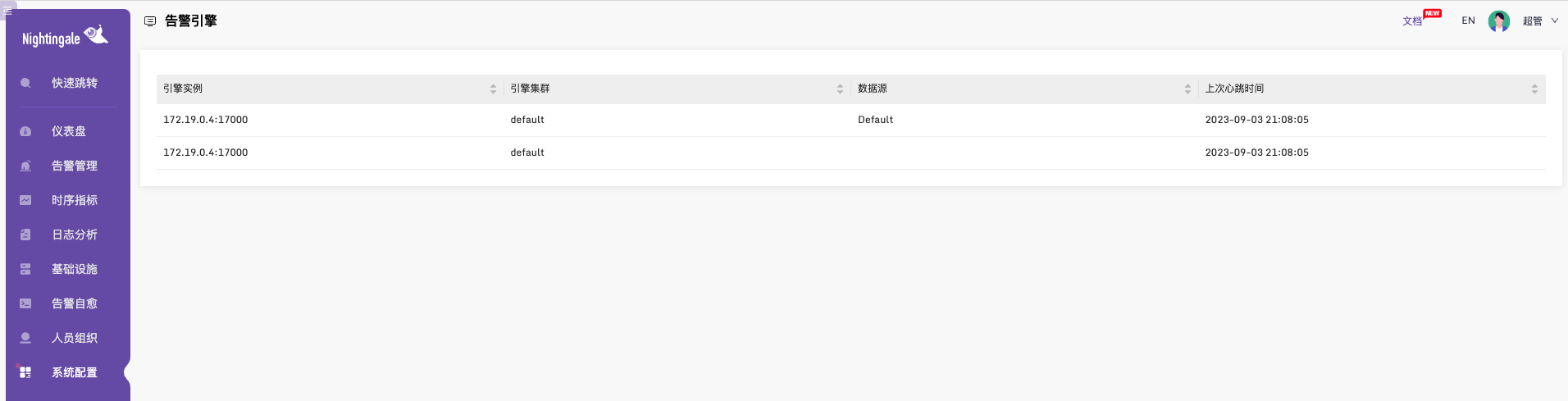
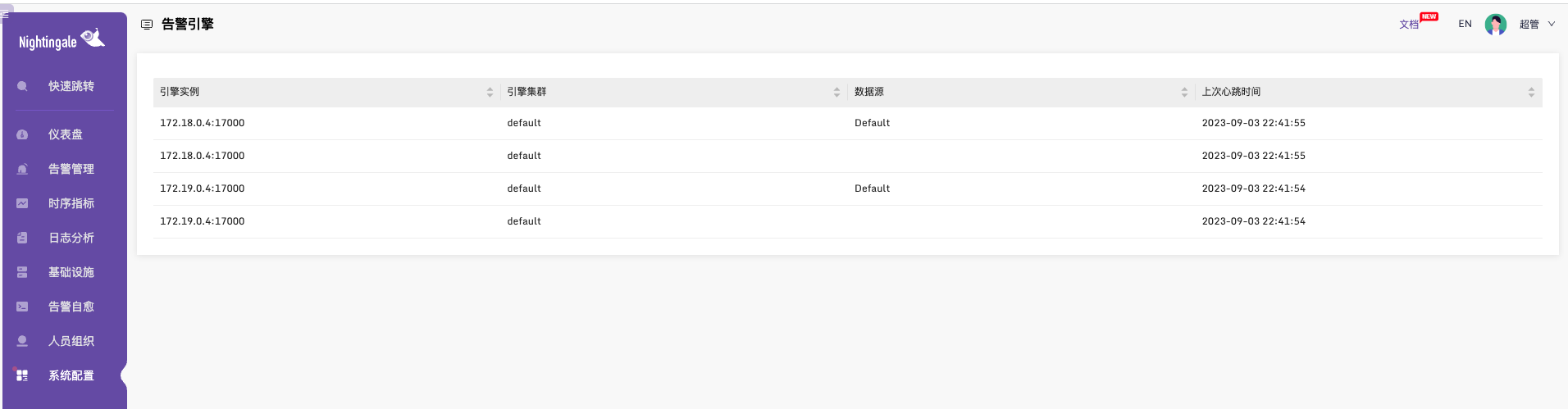
从v5.15.0升级到v6.0.0版本后,同一个告警,在两个n9e节点的日志里看到都触发了,历史告警里出现两条告警
三.配置及详情
1、历史告警

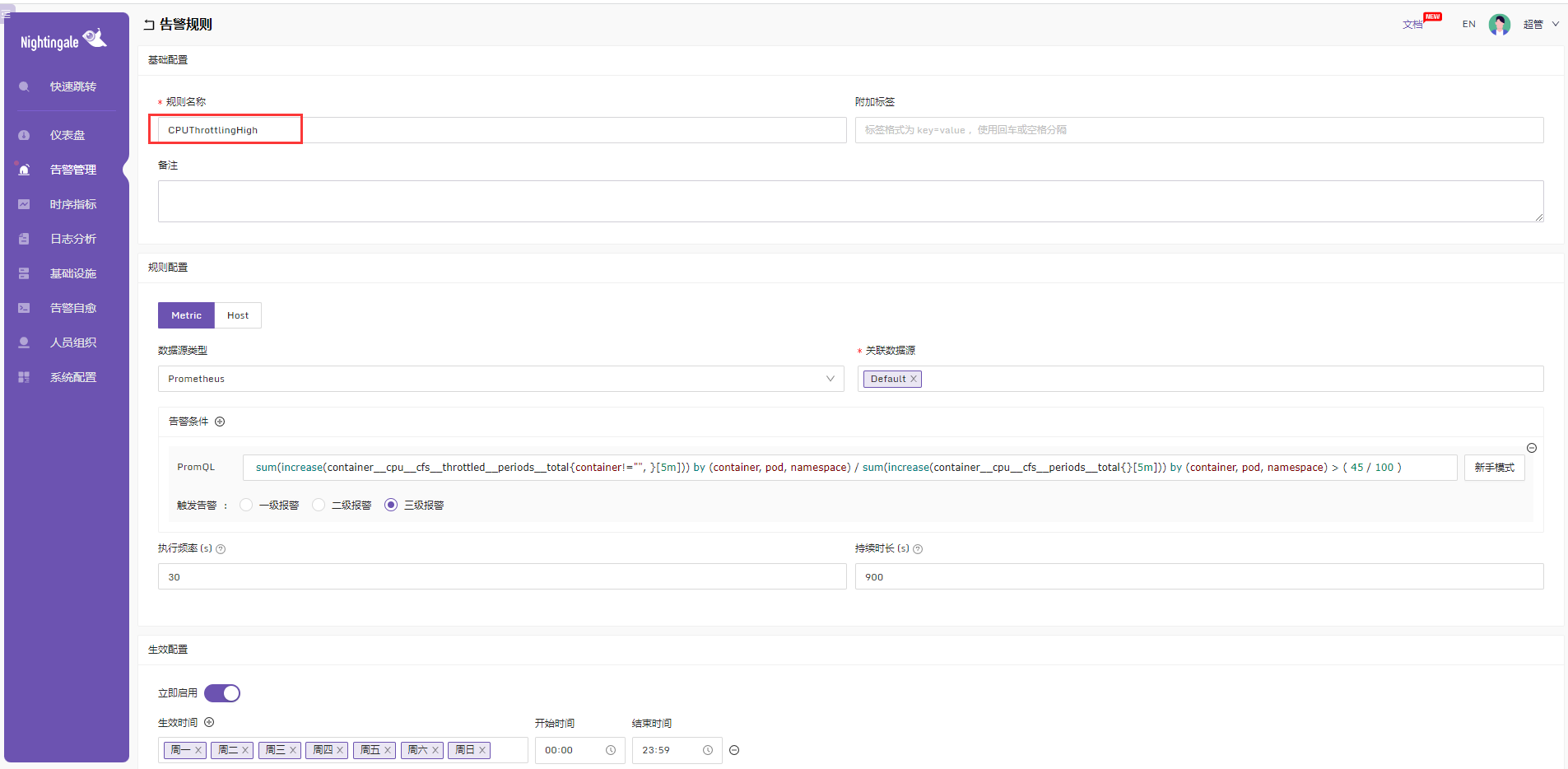
2、告警规则

3、n9e配置,config.toml文件
[Global]
RunMode = "release"
[Log]
Dir = "logs"
Level = "DEBUG"
Output = "stdout"
[HTTP]
Host = "0.0.0.0"
Port = 17000
CertFile = ""
KeyFile = ""
PrintAccessLog = false
PProf = false
ExposeMetrics = true
ShutdownTimeout = 30
MaxContentLength = 67108864
ReadTimeout = 20
WriteTimeout = 40
IdleTimeout = 120
[HTTP.ShowCaptcha]
Enable = false
[HTTP.APIForAgent]
Enable = true
[HTTP.APIForService]
Enable = true
[HTTP.APIForService.BasicAuth]
user001 = "ccc26da7b9aba533cbb263a36c07dcc5"
[HTTP.JWTAuth]
SigningKey = "5b94a0fd640fe2765af826acfe42d151"
AccessExpired = 1500
RefreshExpired = 10080
RedisKeyPrefix = "/jwt/"
[HTTP.ProxyAuth]
Enable = false
HeaderUserNameKey = "X-User-Name"
DefaultRoles = ["Standard"]
[HTTP.RSA]
OpenRSA = false
RSAPublicKeyPath = "/etc/n9e/public.pem"
RSAPrivateKeyPath = "/etc/n9e/private.pem"
RSAPassWord = ""
[DB]
DSN="root:xxxxx@tcp(x.x.x.x:3306)/n9e_v5?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
Debug = false
DBType = "mysql"
MaxLifetime = 7200
MaxOpenConns = 150
MaxIdleConns = 50
TablePrefix = ""
[Redis]
Address = "x.x.x.x:6379"
Password = "xxxxx"
RedisType = "standalone"
[Alert]
[Alert.Heartbeat]
IP = ""
Interval = 1000
EngineName = "default"
[Center]
MetricsYamlFile = "./etc/metrics.yaml"
I18NHeaderKey = "X-Language"
[Center.AnonymousAccess]
PromQuerier = true
AlertDetail = true
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://vminsert.test.com/insert/0/prometheus/api/v1/write"
BasicAuthUser = ""
BasicAuthPass = ""
Headers = ["X-From", "n9e"]
Timeout = 10000
DialTimeout = 3000
TLSHandshakeTimeout = 30000
ExpectContinueTimeout = 1000
IdleConnTimeout = 90000
KeepAlive = 30000
MaxConnsPerHost = 0
MaxIdleConns = 100
MaxIdleConnsPerHost = 100
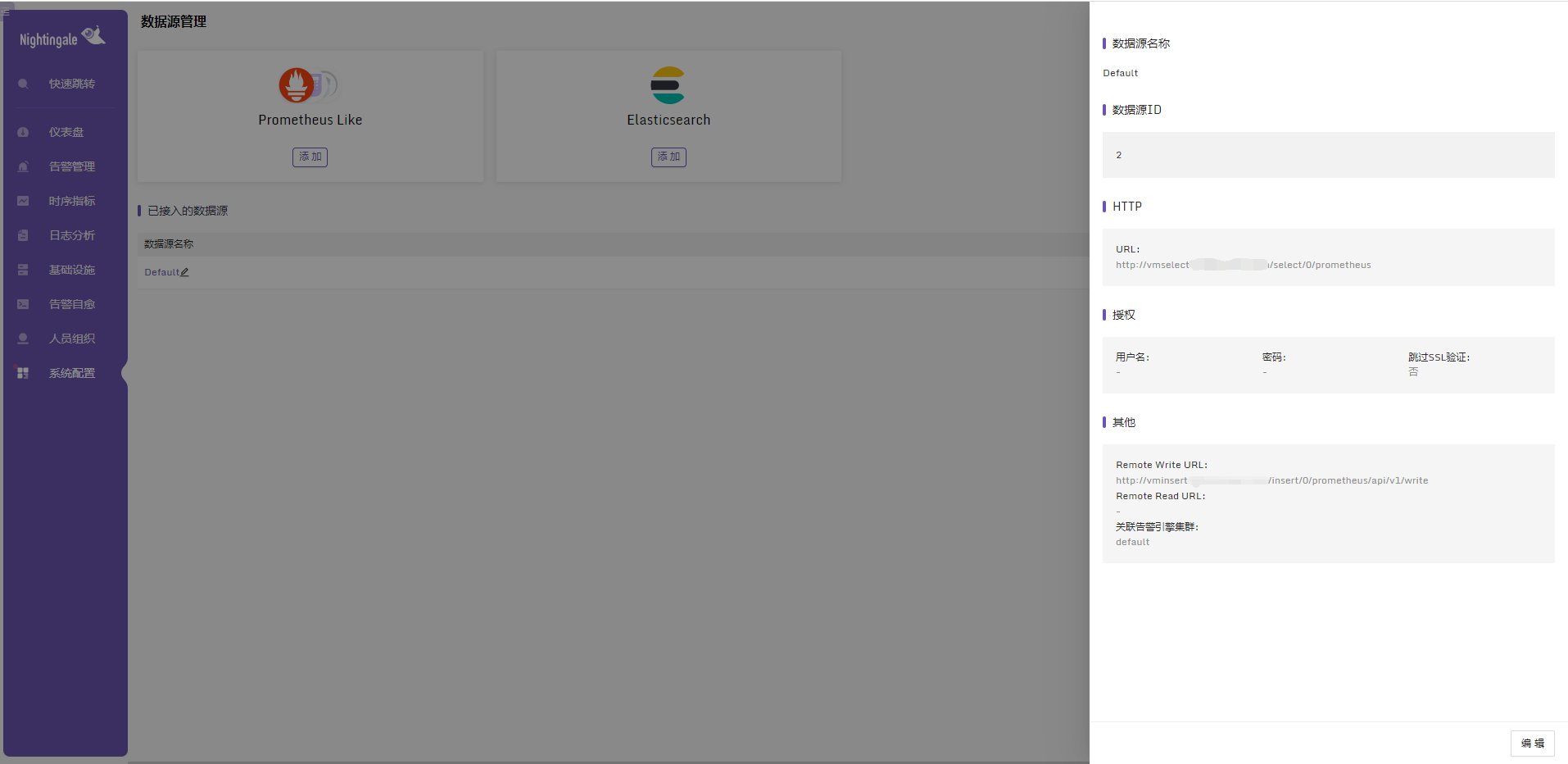
4、数据源
5、n9e的docker-compose文件
version: "3.7"
networks:
nightingale:
driver: bridge
services:
n9e:
image: "flashcatcloud/nightingale:6.0.0"
container_name: n9e
hostname: n9e
restart: always
environment:
GIN_MODE: release
TZ: Asia/Shanghai
WAIT_HOSTS: n9e-mysql:3306, n9e-redis:6379
volumes:
- ./n9eetc:/app/etc
- ./integrations:/app/integrations
ports:
- "17000:17000"
networks:
- nightingale
depends_on:
- n9e-mysql
- n9e-redis
extra_hosts:
- "vmselect.test.com:x.x.x.x"
- "vminsert.test.com:x.x.x.x"
command: >
sh -c "/wait && /app/n9e"