我创建了一个订阅规则,回调地址写的是我自己开发的一个功能系统,但夜莺好像没有给这个地址发送告警信息系。请教一下,夜莺给回调地址发送告警信息是用POST方法吗?还是其他的?
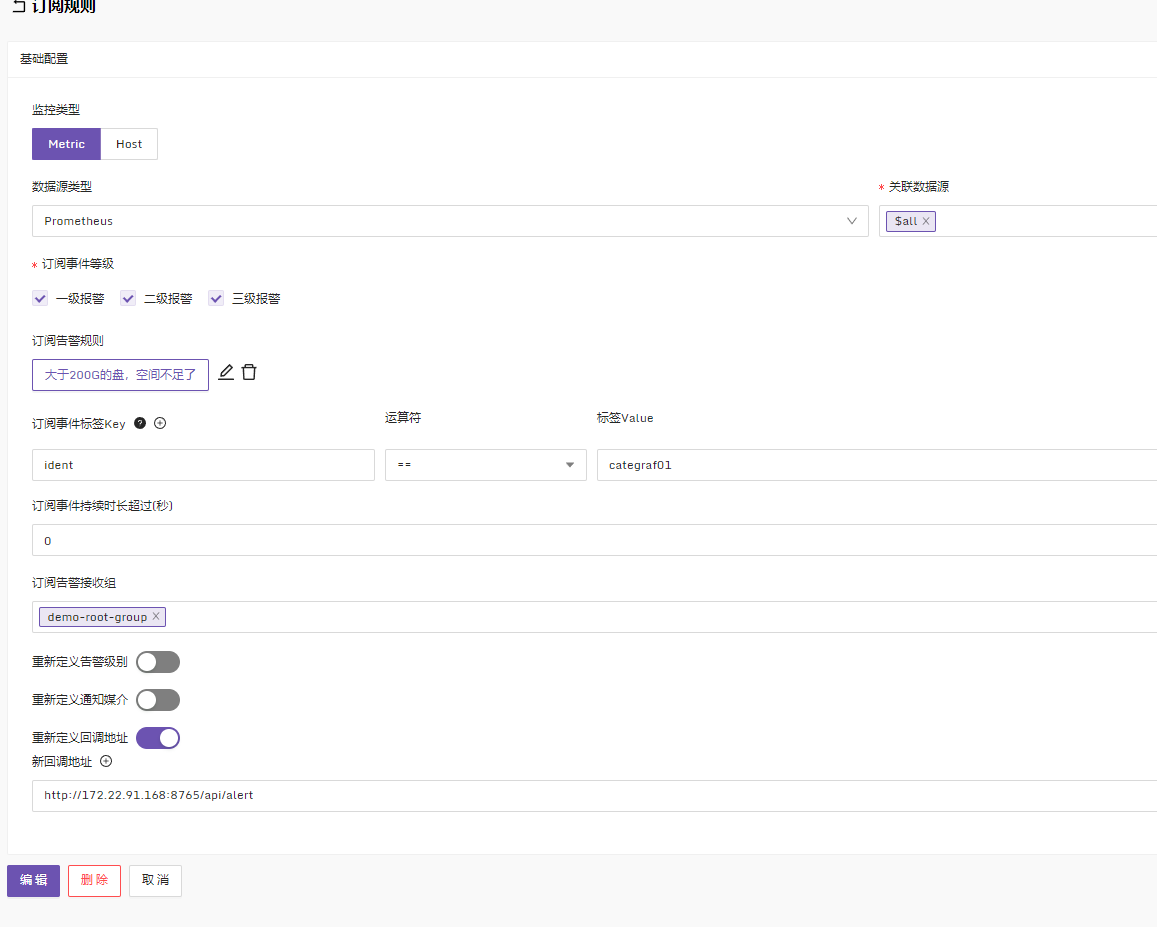
夜莺v6的订阅规则怎么用啊?晕了
Viewed 79
2 Answers
我是理解的是这样 订阅规则类似告警路由的效果,不会产生活跃告警事件。另外订阅告警规则 和 订阅事件标签Key是交集关系,订阅事件持续时长超过(秒)是单事件的持续时间,可以实现类似告警升级效果
没有产生回调行为话,我想可以按这样顺序排查,1.是否产生告警事件,2.是否符合完全匹配订阅告警条件,3.通知渠道是否可用;4.检索日志是否可疑的部分
回调地址发送告警信息是Post方法(SendCallbacks),结果关键字是‘event_callback_fail/succ(xxxx)’
谢谢,订阅规则的告警以post形式发送到回调地址。发送的数据格式如下:
同时这些告警数据只是在告警第一次报出来的时候发送一次,
map[annotations:map[] callbacks:[http://172.22.91.168:8765/api/alert] cate:prometheus claimant: cluster:prometheus datasource_id:1 extra_config:<nil> first_trigger_time:1.691465415e+09 group_id:1 group_name:Default Busi Group hash:915056c17e0c367518cf0f12bca02ae1 id:60 is_recovered:false last_escalation_notify_time:0 last_eval_time:1.691465415e+09 last_sent_time:1.691465415e+09 notify_channels:[] notify_cur_number:1 notify_groups:[1] notify_groups_obj:[map[create_at:1.691387166e+09 create_by:root id:1 name:demo-root-group note: update_at:1.691388825e+09 update_by:root]] notify_recovered:1 notify_users_obj:[map[admin:true contacts:map[] create_at:1.691387166e+09 create_by:system email: id:1 maintainer:0 nickname:超管 phone: portrait: roles:[Admin] update_at:1.691387166e+09 update_by:system username:root] map[admin:true contacts:map[] create_at:1.691388809e+09 create_by:root email: id:2 maintainer:0 nickname:ww phone: portrait: roles:[Admin] update_at:1.691388809e+09 update_by:root username:ww]] prom_eval_interval:30 prom_for_duration:60 prom_ql:disk_free/1024/1024/1024 < 300 and disk_total/1024/1024/1024 >= 200 rule_algo: rule_config:map[inhibit:true queries:[map[prom_ql:disk_free/1024/1024/1024 < 300 and disk_total/1024/1024/1024 >= 200 severity:3] map[prom_ql:disk_free/1024/1024/1024 < 10 and disk_total/1024/1024/1024 >= 200 severity:2] map[prom_ql:disk_free/1024/1024/1024 < 2 and disk_total/1024/1024/1024 >= 200 severity:1]]] rule_id:2 rule_name:大于200G的盘,空间不足了 rule_note: rule_prod:metric runbook_url: severity:3 status:0 sub_rule_id:2 tags:[device=drvfs fstype=9p ident=categraf01 mode=rw path=/mnt/c rulename=大于200G的盘,空间不足了 source=categraf] target_ident:categraf01 target_note: trigger_time:1.691465415e+09 trigger_value:242.33307]
另外,当告警恢复时,会向回调地址发送一条告警恢复数据:
map[annotations:map[] callbacks:[http://172.22.91.168:8765/api/alert] cate:prometheus claimant: cluster:prometheus datasource_id:1 extra_config:<nil> first_trigger_time:1.691465415e+09 group_id:1 group_name:Default Busi Group hash:223addbc4416e7d309dc8c87d31f841a id:65 is_recovered:true last_escalation_notify_time:0 last_eval_time:1.691473827e+09 last_sent_time:0 notify_channels:[] notify_cur_number:2 notify_groups:[1] notify_groups_obj:[map[create_at:1.691387166e+09 create_by:root id:1 name:demo-root-group note: update_at:1.691388825e+09 update_by:root]] notify_recovered:1 notify_users_obj:[map[admin:true contacts:map[] create_at:1.691387166e+09 create_by:system email: id:1 maintainer:0 nickname:超管 phone: portrait: roles:[Admin] update_at:1.691387166e+09 update_by:system username:root] map[admin:true contacts:map[] create_at:1.691388809e+09 create_by:root email: id:2 maintainer:0 nickname:ww phone: portrait: roles:[Admin] update_at:1.691388809e+09 update_by:root username:ww]] prom_eval_interval:30 prom_for_duration:60 prom_ql: rule_algo: rule_config:map[inhibit:true queries:[map[prom_ql:disk_free/1024/1024/1024 < 30 and disk_total/1024/1024/1024 >= 2000 severity:3] map[prom_ql:disk_free/1024/1024/1024 < 10 and disk_total/1024/1024/1024 >= 2000 severity:2] map[prom_ql:disk_free/1024/1024/1024 < 2 and disk_total/1024/1024/1024 >= 2000 severity:1]]] rule_id:2 rule_name:大于200G的盘,空间不足了 rule_note: rule_prod:metric runbook_url: severity:3 status:0 sub_rule_id:2 tags:[device=sdc fstype=ext4 ident=categraf01 mode=rw path=/snap rulename=大于200G的盘,空间不足了 source=categraf] target_ident:categraf01 target_note: trigger_time:1.691473389e+09 trigger_value:230.57958]