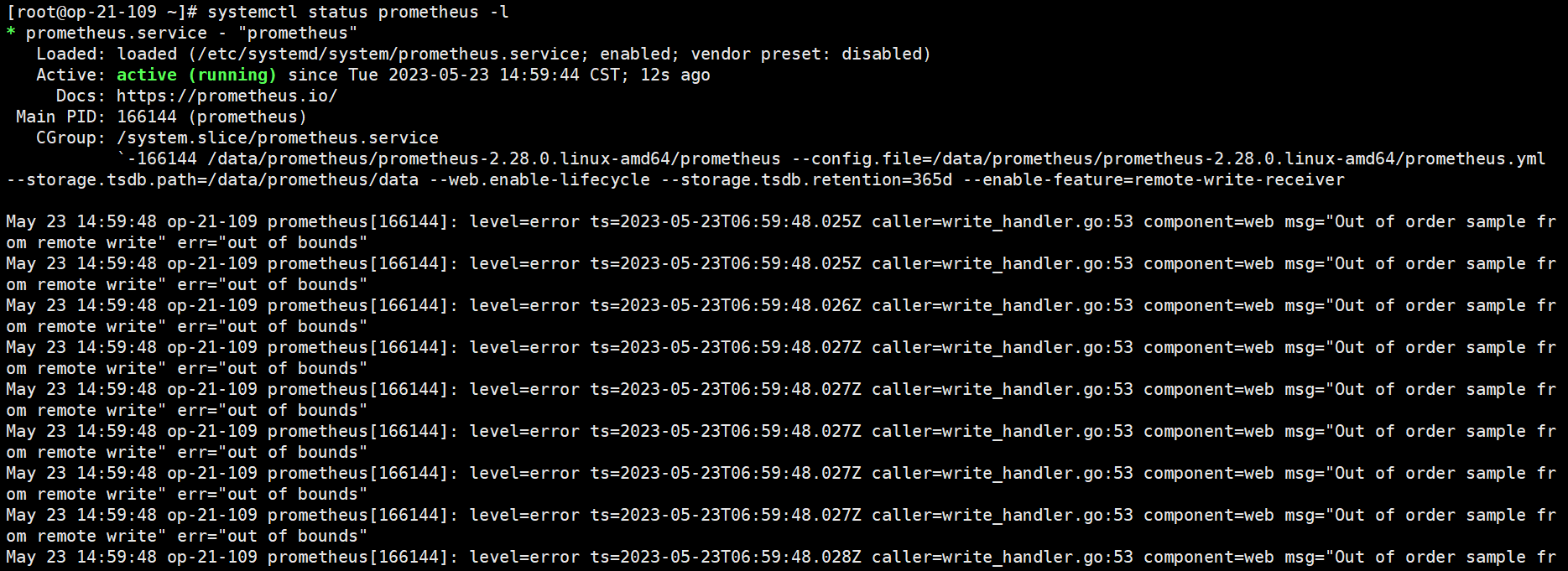
重启了服务端的服务,也没用,不清楚是那一块出了问题,看prometheus 的数据,是从昨天晚上六点半数据采集不到的。客户端的telegraf 服务正常,重启了也不行。

重启了服务端的服务,也没用,不清楚是那一块出了问题,看prometheus 的数据,是从昨天晚上六点半数据采集不到的。客户端的telegraf 服务正常,重启了也不行。
检查一下客户端到服务端的网络以及各自的防火墙,selinux等
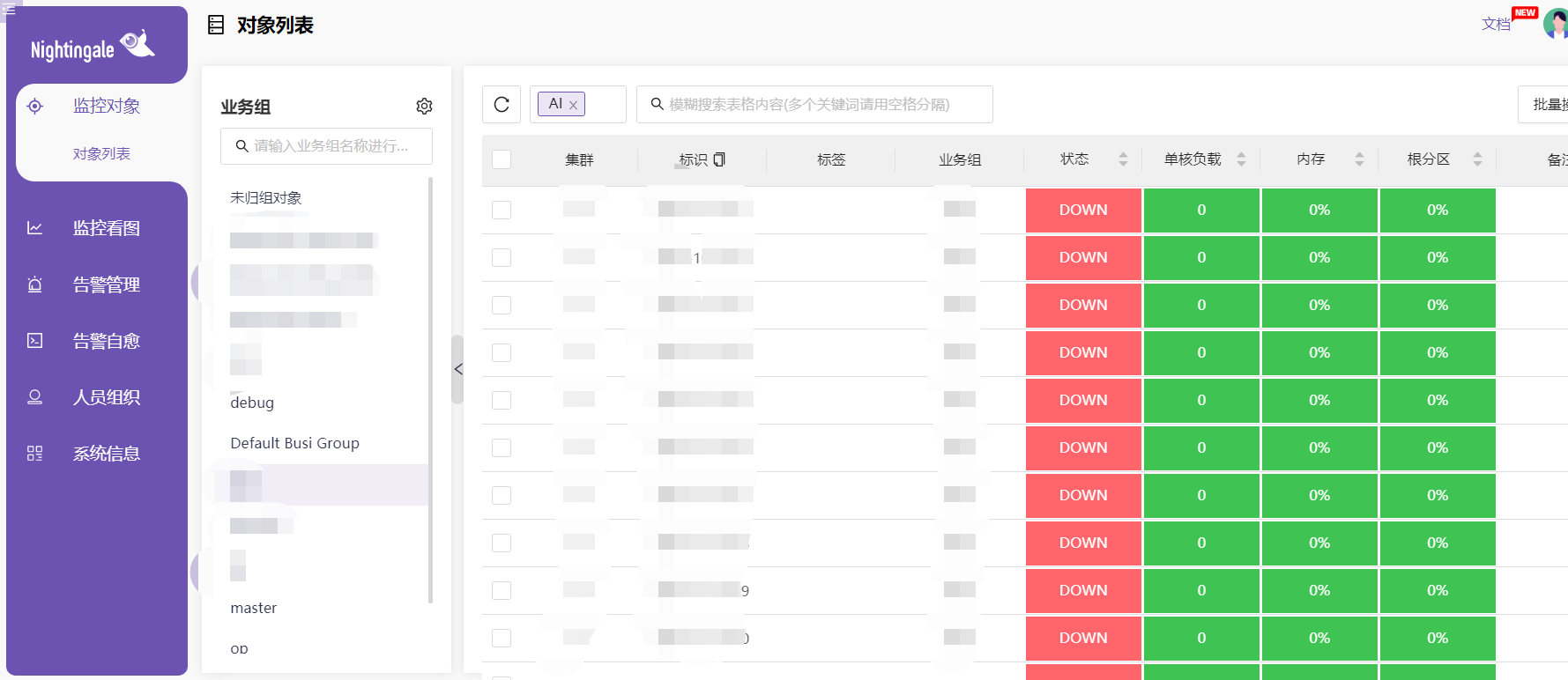
up/down切换是最近上报数据的时间判断出来的,默认是 2 分钟内接收过监控数据 参考官网这篇机器列表(对象列表)数据异常是为什么?
嗯,就是所有的机器都不上报数据了,服务端还是v5的版本,采集器用的telegraf,查看客户端和服务端的服务正常,就很懵
out of bounds ,把所有机器的时间校准一致。注意,你的浏览器所在机器的时间和你的夜莺的机器的时间也要一致
同样的问题,没找到解决办法,暂时给prometheus换了个数据目录,目前新的数据上来了。
说明是之前的数据有问题,至于怎么修复,或者如何把之前的数据合并过来,暂时没顾上研究。
这种不知道是不是prometheus数据库本身的原因,就是一旦有一台机器或者时序数据库某个时间点遇到问题只能把整个目录删除&给prometheus换了个数据目录,我目前只能多试,不太清楚其中的原因。
问题描述:
1.由于Prometheus是时序数据库,根据时间戳的方式进行数据的采集和持久化。
2.下面问题发生是因为就是数据采集节点dps和服务节点系统n9e-server时间差距太大引起的,需要控制在30s内。太多的乱序数据进入Prometheus会导致Prometheus服务停止服务。
解决:
#因为n9e和Prometheus在一台机器上,节点数据是先上报到n9e在rewrite到Prometheus中所以在啊n9e的配置中添加
ForceUseServerTS = true #要求节点的时间戳改为本机的时间戳。大大减少了错误率