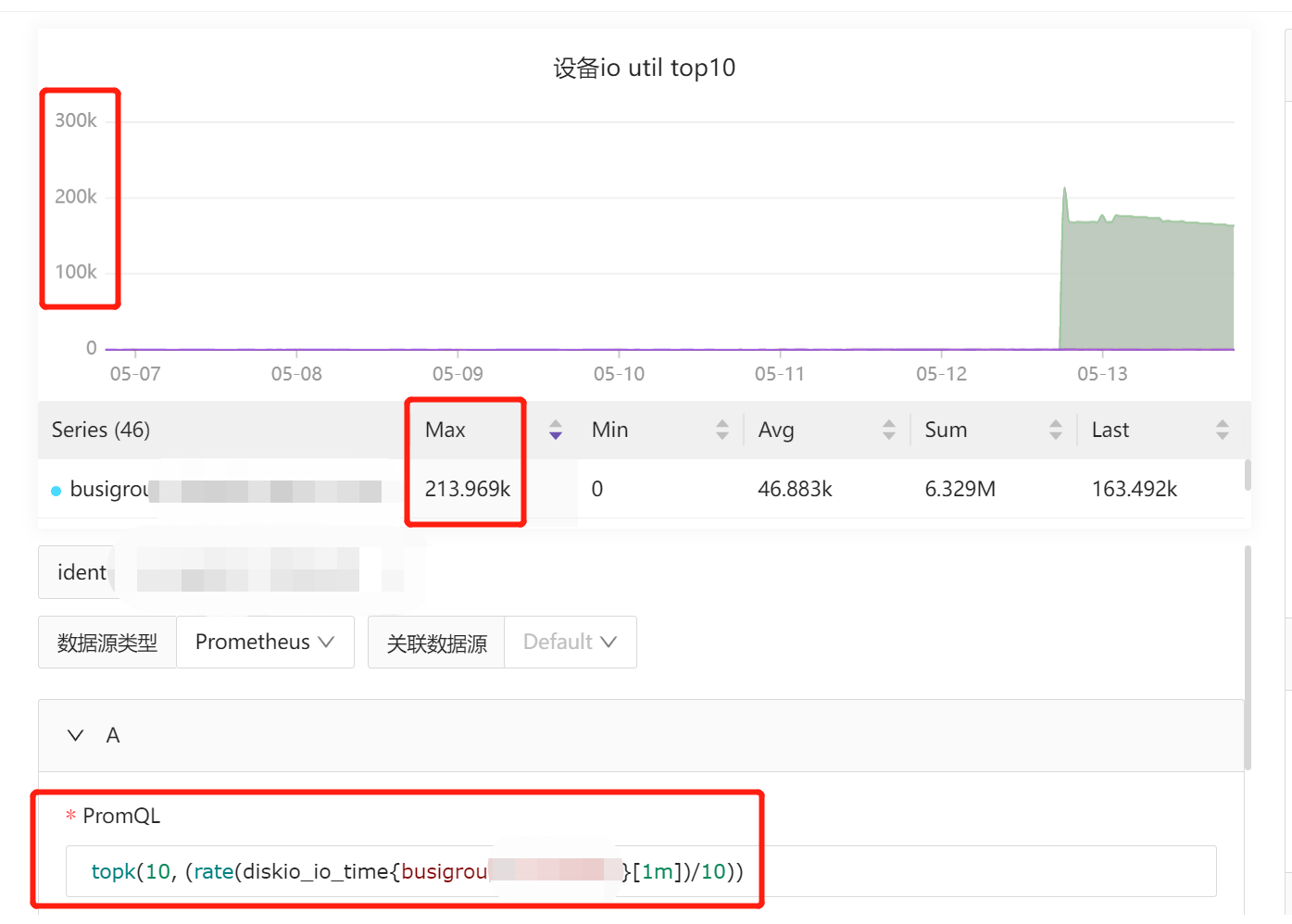
请问 这个Linux Host by Categraf 中的 io util top10
topk(10, (rate(diskio_io_time{busigroup="xxxx"}[1m])/10))
指标是根据什么来的
通过查看阿里云 监控 vda磁盘没有异常 但是 监控上指标数值有点太大了。。。
vda是阿里云服务器 默认/ 目录
请问 这个Linux Host by Categraf 中的 io util top10
topk(10, (rate(diskio_io_time{busigroup="xxxx"}[1m])/10))
指标是根据什么来的
通过查看阿里云 监控 vda磁盘没有异常 但是 监控上指标数值有点太大了。。。
vda是阿里云服务器 默认/ 目录
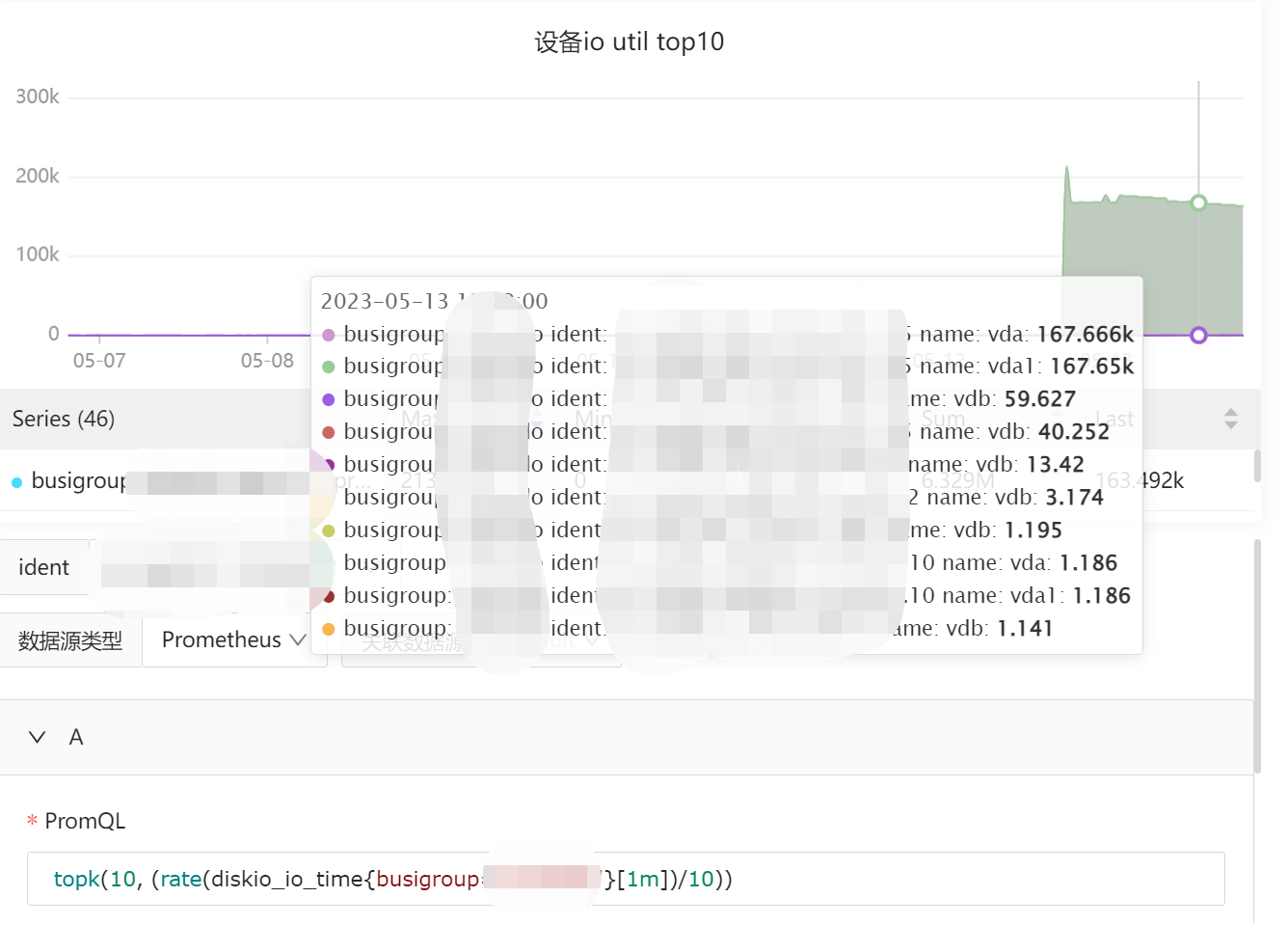
即时查询中查询diskio_io_time{你的问题机器label}[5m] ,这种问题一般是两台机器用了相同的ident导致的
大佬 真乃神人也,确实是 相同ident导致。
同事用此 ident服务器克隆了两台主机 ...
kongfei大佬 真乃神人也
kongfei大佬 真乃神人也
kongfei大佬 真乃神人也
我从官网找到这个,Telegraf调研笔记2:CPU、MEM、DISK、IO相关指标采集 ,数值太大是不是因为查询选择器不合适,按照文章解释rate(diskio_io_time[1m])/10 是IO使用率,每秒有多少零点几秒是用于io,即io的时间占比,比率一般用%单位,所以我觉得应该是按照机器筛选Linux磁盘监控-diskio_io_time
大佬 我观不是单位问题
因为 其它服务器都是好用的,
其他设备在备份大数据库时候 会触发该指标告警
告警规则:rate(diskio_io_time{busigroup="xxxx"}[1m])/10 > 99
就这台 异常 这些服务器 都是克隆的
换了 categraf 版本 也不行。
有可能 重启解决问题 。因为是生产服 不能随时重启 等协调个时间再看看