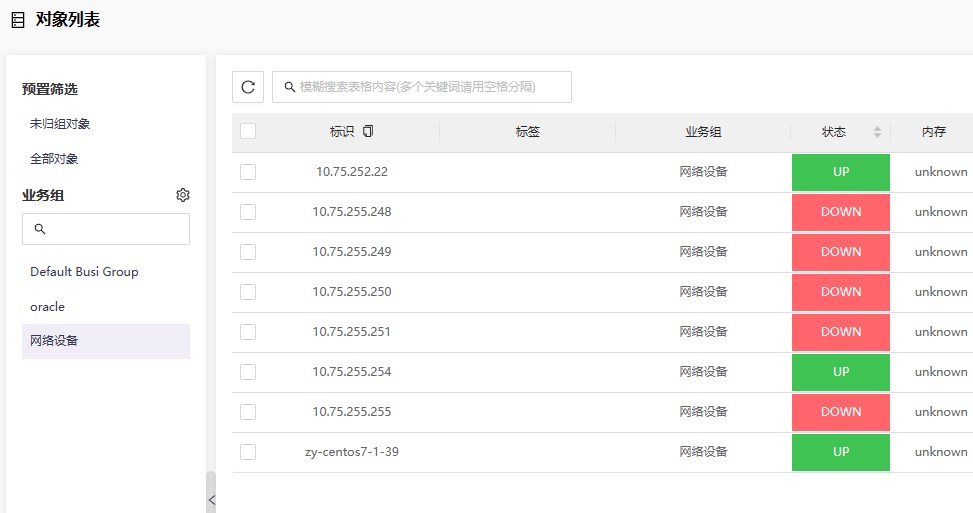
down的设备都是写在同一个inputs.snmp中的,只有这个模块里的设备会这样,其余两个没啥问题,代码是:
[[inputs.snmp]]
agents = [
"10.75.255.255",
"10.75.255.251",
"10.75.255.250",
"10.75.255.249",
"10.75.255.248",
]
timeout = "5s"
version = 3
...
agent_host_tag = "ident"
retries = 1
[[inputs.snmp.field]]
oid = "RFC1213-MIB::sysUpTime.0"
name = "uptime"
[[inputs.snmp.field]]
oid = "RFC1213-MIB::sysName.0"
name = "sysName"
is_tag = true
[[inputs.snmp.table]]
name = "interface"
oid = "IF-MIB::ifTable"
[[inputs.snmp.table]]
name = "interface"
oid = "IF-MIB::ifDescr"
[[inputs.snmp]]
agents = ["10.75.252.22"]
timeout = "5s"
version = 2
community = "public"
agent_host_tag = "ident"
retries = 1
[[inputs.snmp.field]]
oid = "RFC1213-MIB::sysUpTime.0"
name = "uptime"
[[inputs.snmp.field]]
oid = "RFC1213-MIB::sysName.0"
name = "sysName"
is_tag = true
[[inputs.snmp.field]]
name = "ifDescr"
oid = "IF-MIB::ifDescr"
is_tag = true
[[inputs.snmp.table]]
name = "interface"
oid = "IF-MIB::ifTable"
不知道问题出在哪里。


