- 背景信息:夜莺和categraf部署于k8s,metrics由夜莺接收后写入到 VictoriaMetrics 集群。该categraf只启用prometheus插件,专门做Prometheus接口的采集。
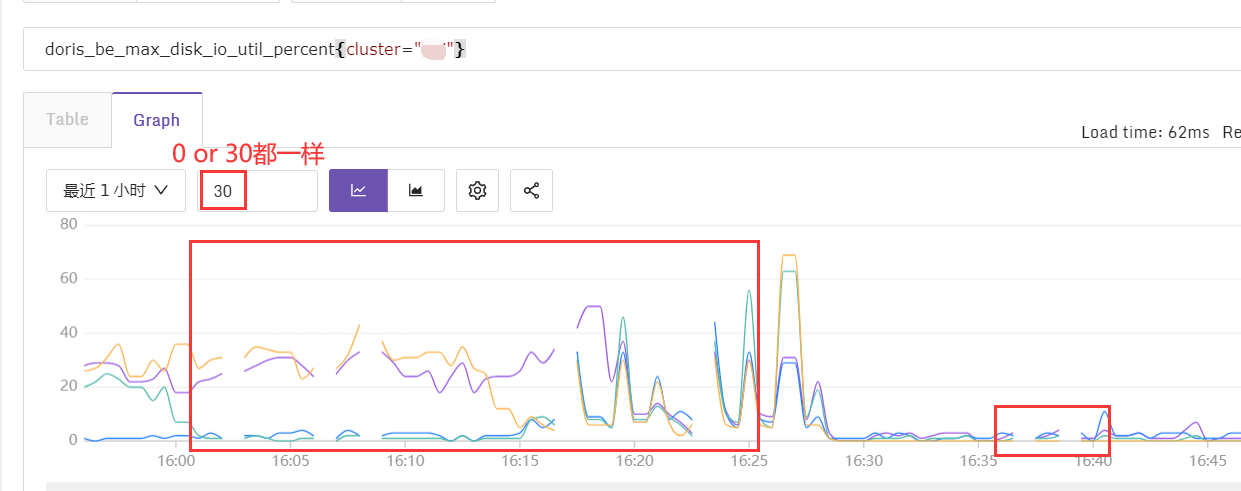
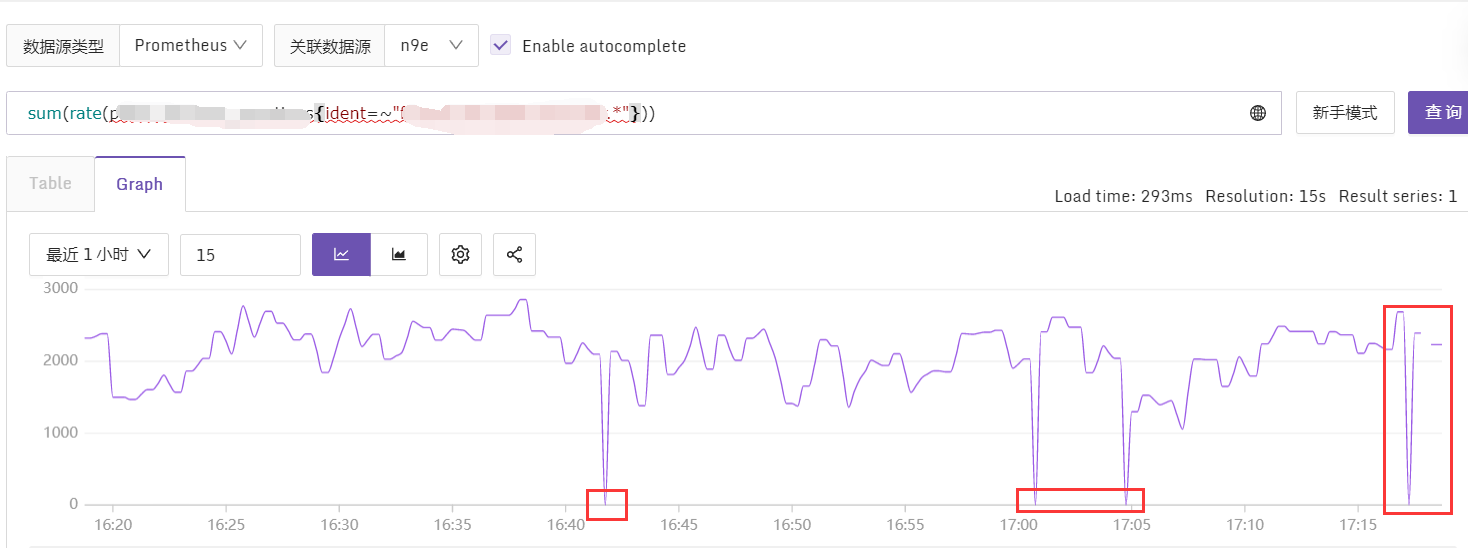
- 问题:约50个地址,几乎每个地址都有丢数据的情况,见下图。categraf日志未见异常。
categraf 基础配置
[global]
print_configs = false
hostname = ""
omit_hostname = true
precision = "ms"
interval = 30
[writer_opt]
batch = 5000
chan_size = 2000000
[[writers]]
url = "http://n9e-server:19000/prometheus/v1/write"
# timeout settings, unit: ms
timeout = 5000
dial_timeout = 2500
max_idle_conns_per_host = 1000
[[instances]]
labels = { ident="master", cluster="aaa", role="master" }
urls = [
"http://machine1:19091/metrics",
"http://machine2:19091/metrics",
"http://machine3:19091/metrics",
"http://machine4:19091/metrics",
"http://machine5:19091/metrics"
]
url_label_key = "instance"
url_label_value = "{{.Host}}"
headers = ["X-From", "monitor"]
timeout = "25s" # timeout for every url
[[instances]]
# Volume Server
labels = { ident="volume", cluster="aaa", role="volume" }
urls = [
"http://machine1:19092/metrics",
"http://machine2:19092/metrics",
"http://machine3:19092/metrics",
"http://machine4:19092/metrics",
"http://machine5:19092/metrics",
"http://machine6:19092/metrics",
]
url_label_key = "instance"
url_label_value = "{{.Host}}"
headers = ["X-From", "monitor"]
timeout = "25s" # timeout for every url
VictoriaMetrics组件启动参数
- vmstorage
vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath /data5/victoria-metrics-data/ -dedup.minScrapeInterval=5s -retentionPeriod=400d -search.maxUniqueTimeseries=1000000 -vminsertAddr=:8400 -vmselectAddr=:8401 -httpListenAddr=:8482
- vmselect
vmselect-prod -storageNode=n1:8401,n2:8411,n3:8401,n4:8411 -dedup.minScrapeInterval=1ms -search.maxSeries=10000000 -search.maxUniqueTimeseries=1000000 vmstorageDialTimeout=15s
- vminsert
vminsert-prod -replicationFactor=2 -maxInsertRequestSize=9999999999 -vmstorageDialTimeout=15s -storageNode=n1:8400,n2:8410,n3:8400,n4:8410
