确定探针每隔15秒都在上报数据,但节点多了之后,大概60多个,此时指标五分钟内数据只有两条,比如mem_free指标。
测试探针上报间隔方法:将prometheous服务停掉,探针每15秒报一次错,如下图所示。

探针每15秒上报一次,但prometheus大概两分钟才存一次数据
Viewed 143
4 Answers
中间是否有prometheus做了remote write
不太明白什么意思,我只有一个prometheous,用的夜莺默认架构,启动参数是./prometheus --config.file=./prometheus.yml --storage.tsdb.path=./data --web.enable-lifecycle --enable-feature=remote-write-receiver --query.lookback-delta=2m
还有人回答我的问题吗
我也遇到一样的问题,采集节点多了以后,图表开始不连续。
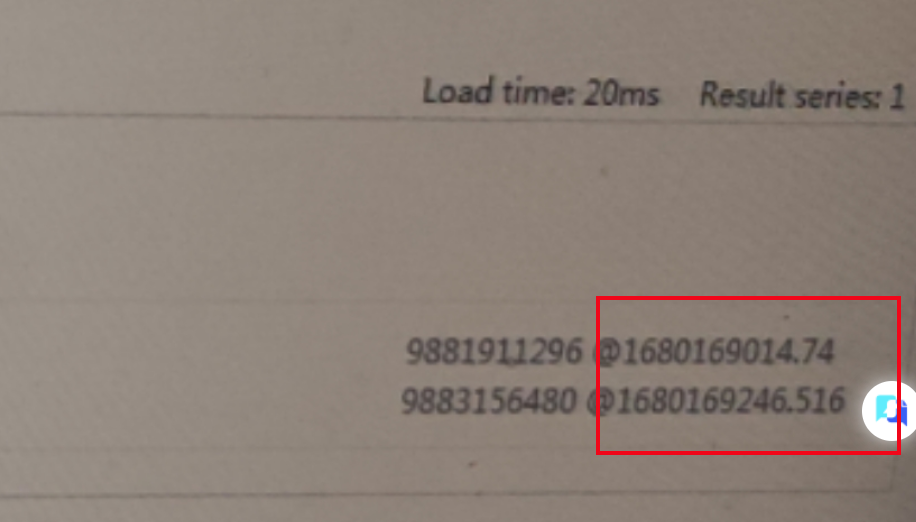
查每5min内只有2个数据
"""
interval = 60
interval_times = 1
"""
修改了主配置config.toml和采集器的插件toml文件后似乎可以了,但是5m偶尔还是只有2个数据导致图表不连续
注销掉TABLE下的oid,只配置需要获取数据的field的OID,这样彻底解决了数据不连续的问题。
原先获取一次table数据需要60-70s,现在15s就可以完成一次获取
[[instances.table]]
## oid = "IF-MIB::ifTable"
name = "interface"
[[instances.table.field]]
oid = "IF-MIB::ifDescr"
name = "ifDescr"
is_tag = true
销掉TABLE下的oid,请问这个配置文件路径是哪里呀?