我是通过下面的配置进行/var/log/messages文件的错误日志监控的,现在发现一个问题,当messages文件定时产生
Apr 6 18:00:09 mt-hermesContract-101 crond: sendmail: warning: inet_protocols: disabling IPv6 name/address support: Address family not supported by protocol
Apr 6 18:00:09 mt-hermesContract-101 crond: postdrop: warning: inet_protocols: disabling IPv6 name/address support: Address family not supported by protocol
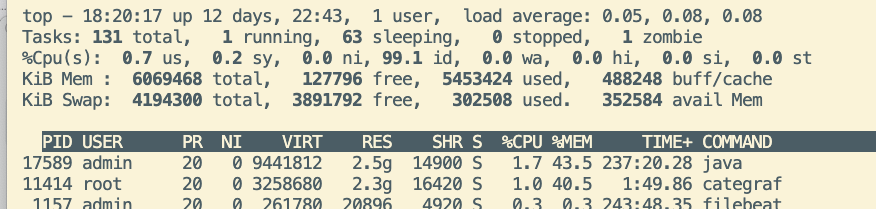
这种错误的时候,categraf占用的内存会一直增长
categraf 版本为0.2.31.
system.mtail配置文件如下:
# file BlockForMore.mtail:
counter system_blocked_morethan_error
/blocked for more than/ {
system_blocked_morethan_error++
}
# file BUGHardareLookup.mtail:
counter system_hardlookup_bug
/Hard LOCKUP/ {
system_hardlookup_bug++
}
# file BUGSoftLookup.mtail:
counter system_softlookup_bug
/BUG: soft lockup/ {
system_softlookup_bug++
}
# file CallTrace.mtail:
counter system_call_trace_error
/Call Trace/ {
system_call_trace_error++
}
# file HardwareError.mtail:
counter system_hardware_error
/Hardware Error/ {
system_hardware_error++
}
# file KernelBug.mtail:
counter system_kernel_bug
/kernel BUG at/ {
system_kernel_bug++
}
# file KernelPanic.mtail:
counter system_kernel_panic_error
/Kernel panic/ {
system_kernel_panic_error++
}
# file MemoryCgroupOutOfMemory.mtail:
counter cgroup_out_of_memory_error
/Memory cgroup out of memory/ {
cgroup_out_of_memory_error++
}
# file OutOfMemory.mtail:
counter system_out_of_memory_error
/Out of memory/ {
system_out_of_memory_error++
}
# file UnableHandleKernel.mtail:
counter system_unable_handle_kernel_error
/BUG: unable to handle kernel/ {
system_unable_handle_kernel_error++
}
mtail 插件配置:
[root@mt-tfFileConvert-101 ~]# cat /httx/run/categraf/conf/input.mtail[[instances]]
progs = "/httx/run/categraf/progs/system.mtail" # prog dir1
logs = ["/var/log/messages"]
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" #string type
# [[instances]]
# progs = "/path/to/prog2" # prog dir2
# logs = ["/path/to/logdir/"]
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" # string type
现在是偶发的几台服务器出现categraf内存泄露问题,看categraf日志找到如下日志
2023/04/06 15:48:51 collector.go:74: I! Everything is ready for traces, begin tracing.
2023/04/06 16:48:51 store.go:157: Running Store.Expire()
出现store.go的日志之后,categraf进程内存会增加占用,然后查代码发现,store.go是mtail使用的,倒查发现了messages的报错,而且出现内存泄露的服务器都有这个问题,其他正常服务器是关闭系统邮件服务的
经过定位排查,发现是trace链路数据采集的问题,数据量大会产生堆积,导致内存泄露,优化配置解决
感谢反馈,categraf又清白了 /doge