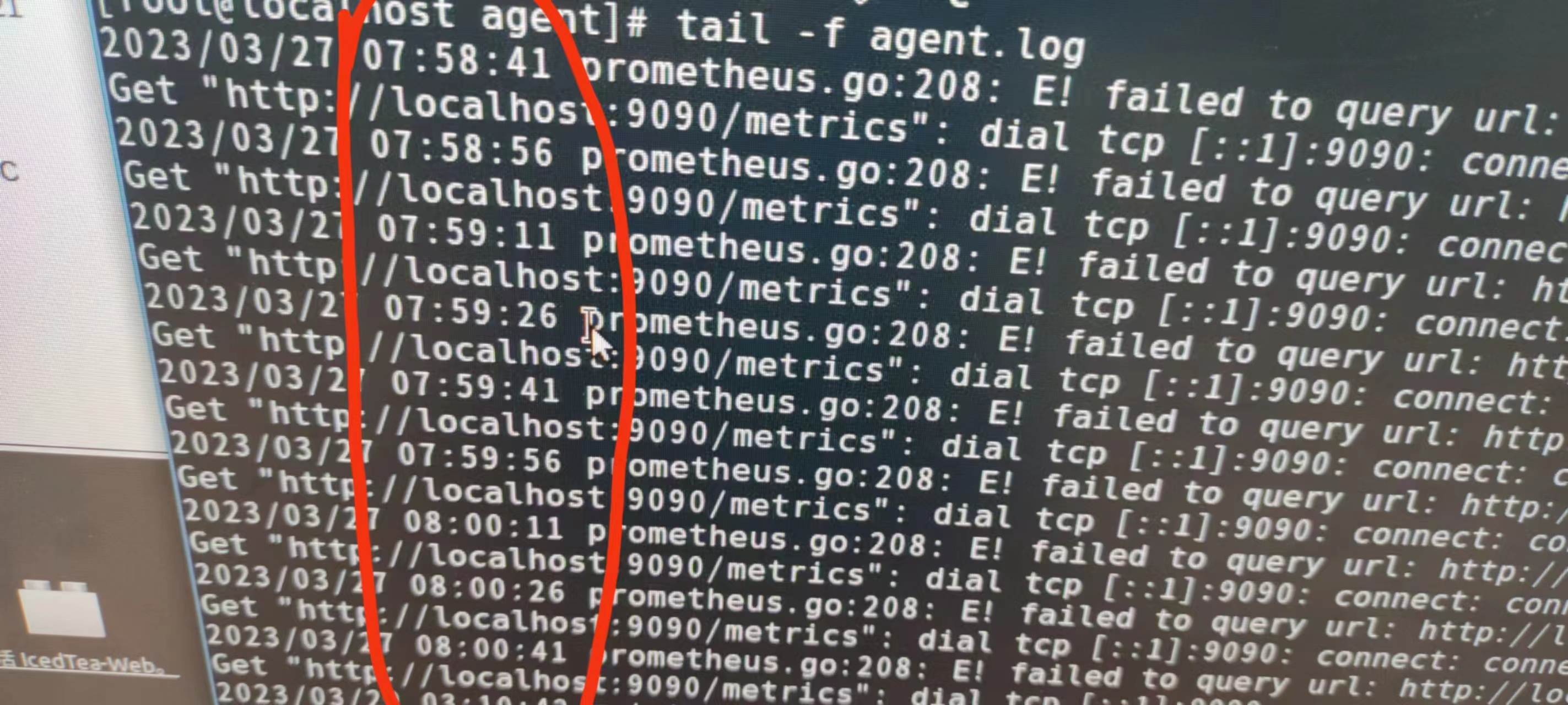
所有探针数据都是时断时续的,要断一起断,和服务端部署在一起的探针也是这样。
大概每隔两分钟就断两分钟,断的这段时间prometheus没数据。
请问是什么原因造成的?
所有探针数据时断时续
Viewed 119
6 Answers
可以看看日志哈,只有这些信息无法判断,每个相关模块的日志都看看

这是图表展示效果,时序图不连续
你找一个断线的指标,比如mem_free,在即时查询里查一下最近5分钟的数据,用table视图,比如:mem_free[5m]然后截个图我看看。不按照我说的来,我帮不了你哈~~
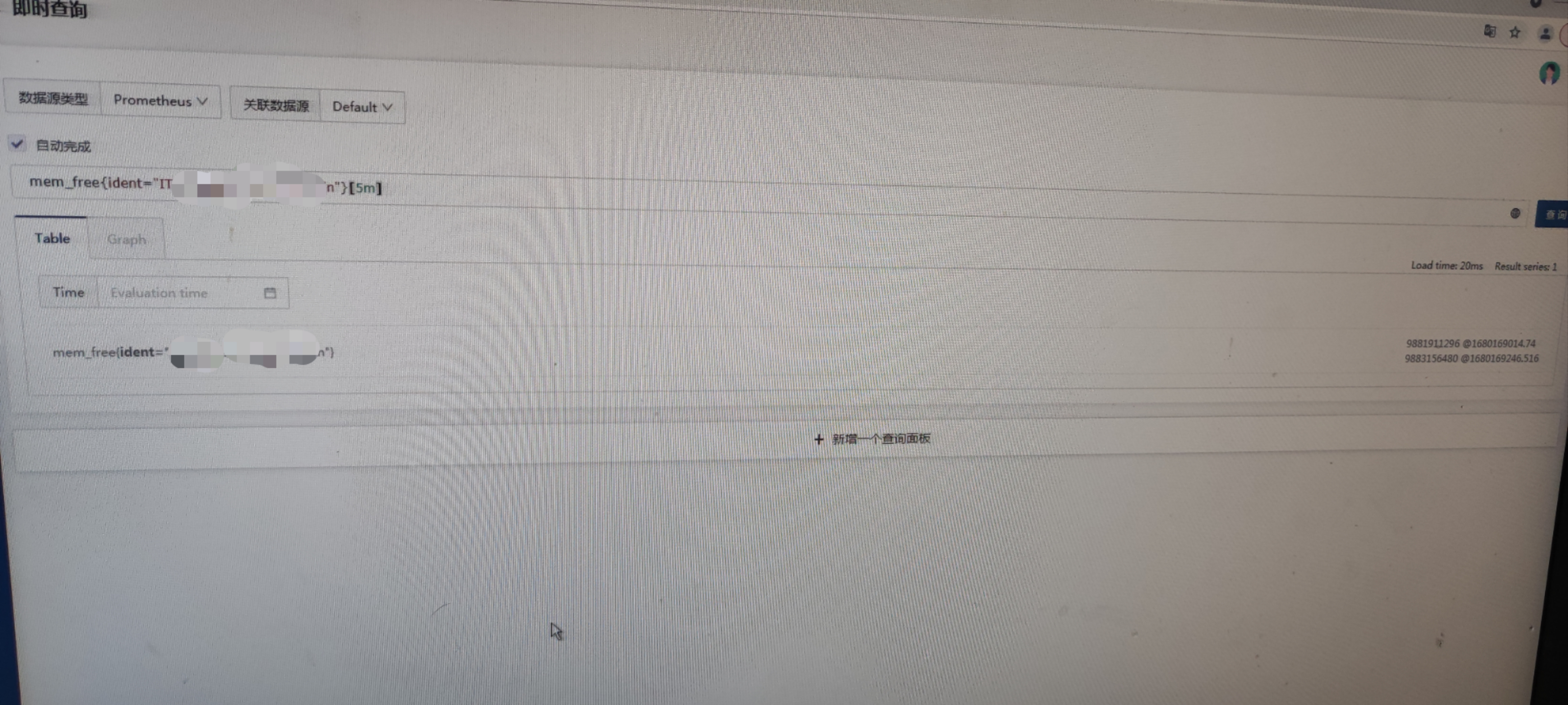
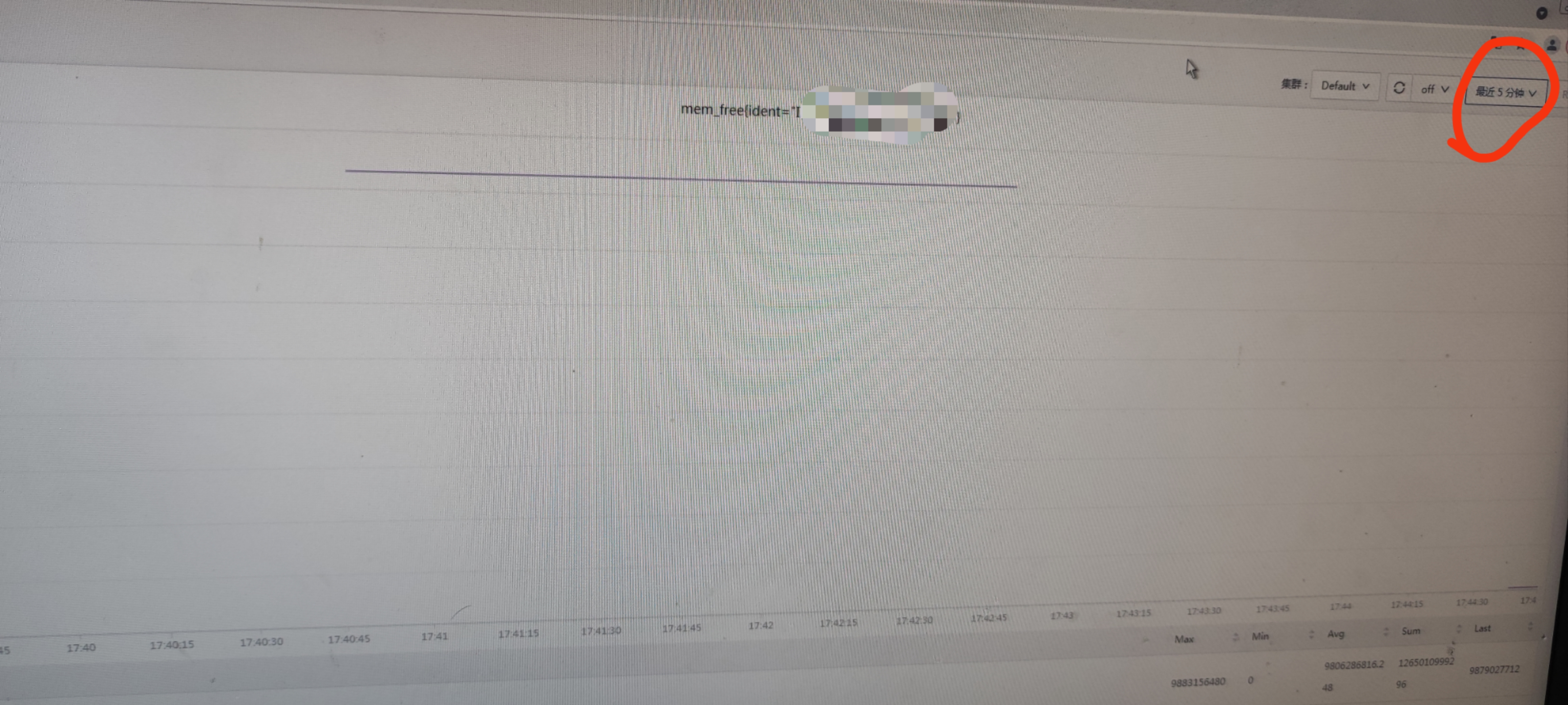
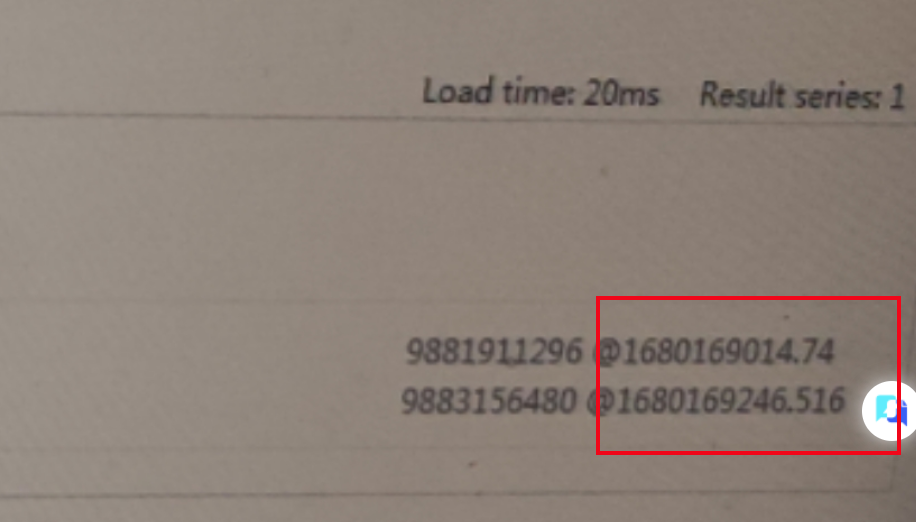
你看你最近5分钟只有2个点上报,显然前面说的categraf 15s上报一次这个前提就不成立。table视图明显可以看出,上报频率是232左右,你现在要去追查为啥上报频率不是15s,如果确保上报的频率是15s,就不会断线了,理论上上报频率小于2m(根据prometheus的启动参数可以判断)都不会断线
over
非常感谢您的帮助,上报限制主要是探针控制的吗,我重点关注categraf